Hello - Could you give me a clue as to how the duplicate detection is supposed to work? My library is not indicating that I have any duplicates - but I’ve just found about a dozen that I have had to manually edit and then send to trash. The titles are identical (although some have varying cases) in all the ones I found, as are some of the other details such as author or journal. I have tried copying some fields from one to another to try to provoke the duplicate detector but it doesn’t seem to want to co-operate today.
As an alternative could you include some easy user driven mechanism for identifying duplicates that could then be merged in the normal manner?
Thanks for the query, @jmw. As @T_Verron points out, the best way to trigger our system’s duplicate detection is to add a unique identifier (like DOI or URL) to both - it could even be a made-up number or random link which one can delete once the records are merged.
I realize this is just a workaround; improving our duplicate detection and implementing a clearer mechanism for users to identify and merge records easily is on our wishlist. Adding your +1 to the topic as usual to raise its priority on our tracker.
Thanks both. I have used the copying the doi before to get over this. The problem with that method is that although it is effective if both records have the doi field, I’m finding that a lot of my duplicates are conference papers which have somehow set themselves up as both a ‘Book Chapter’ (with no doi or URL field) and also as a ‘Journal Article’ which has both. To copy one or the other to the other duplicate record first involves adding a new doi field to the ‘Book Chapter’ one, and then copying it across. This makes it an even slower and more painful process - hence my asking what fields were used to detect duplicates. Or for any easier way around it.
And yes, it is definitely Paperpile that is making these classifications when I import the papers - I rarely make any changes to the records.
Out of curiosity, does auto-updating such items without DOI and URL have any effect? If it does, that might relieve you from having to manually copy such fields over for merging.
Thanks for the input @kernel - I don’t think so, but can’t confirm this at the moment. I have been trying to deduplicate as I come across items, and I’m pretty sure that I would have tried that.
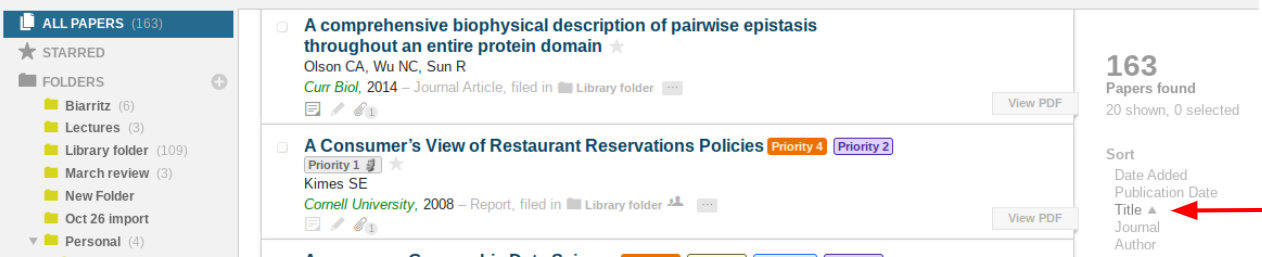
I did try to test this out earlier, but one thing that does hamper the search for other duplicates is that the only sort option available for ‘All Papers’ is by date added. @stefan - would it be possible to sort the entire library by case insensitive title?
@kernfel auto-updating items without DOI / URL could have effect but depends on too many varying factors. It’s complicated to predict whether it will work but it’s definitely worth a try for anybody on @jmw’s position - simply selecting the references and hitting Shift+A will do the trick. Besides attempting to match DOI, URL, title and author names, we also create a synthetic value from metadata fields title, booktitle and author to identify duplicates.
@jmw is there no ‘Title’ option under Sort in the right-hand side column like below?
@vicente - Sadly there isn’t. ‘Title’ sort only appears if I include a filter such as Notes or Unsorted. If I don’t select one ( or try ‘Has PDF’ or ‘Has no PDF’) my only sort option is ‘Date Added’
Oh… Thanks for that useful nugget of information @vicente. Could that limit be removed at any point? I can’t guarantee that any of the other potential duplicates that may be in there would have the same labels or be in the same folder. I’ve already discovered that some of the duplicates have different ‘Types’ assigned to them, so I can’t see any other easy way to identify them.
Failing that could we have the ability to identify papers as duplicates ourselves, that could then be merged by the existing PaperPile method?
Duplication is an issue for me too, my library is still small but will be growing over the next few years. I just tried doing the DOI thing. I used a unique DOI copied it to both entries, selected and tried auto updating and they didn’t merge. Any ideas on why?
Apologies for not getting back to you here @jmw! Of course, same as we’re working to implement more powerful search features, we hope to eventually grow beyond this and other limits.
As I mentioned above, implementing the ability to manually flag and merge duplicates is well within our plans. Among other things, we’re currently working on a complete rewrite of our sharing system which will lead us to look at duplicate handling as well.
Thank you so much! I never saw the duplicate filter and the merge option. I was basing my tries on people trying to get to similar citations to report as duplicates. This works well!
Regarding duplications, I find that every time a paper is cited using paperpile, a copy is created in the library, causing multiple duplicates. For example, if XYZ2021 is cited 10 times, there will be 10 copies of this study in the paperpile library, and in the Google Drive Paperpile folder. Deleting the duplicates will cause an error in the citation, for the link will be broken. I have tested this to be true, as restoring the trashed paper restored the link to a specific reference of the same paper. Meaning, each duplicated reference is tied to a specific copy of the same paper in the Paperpile library.
It appears the only workaround is to copy the existing Papepile reference link to use whenever a paper is cited a second/third time, instead of generating a new link. However, that defeats the purpose of using Paperpile, which is to facilitate duplication in numbering.
I hope this can be resolved. Otherwise, a paper with 2000 citations will require a lot of manual work to remove duplications.
@Doris_Loh could you share the specific steps of your citing workflow in Google Docs, or perhaps a screen recording showing how the duplication occurs? Are you using the extension (Ctrl-Shft-P shortcut) or the optional sidebar add-on? What you describe is not at all expected behavior so we need to find out what’s causing that on your end. If you’re logged in to any other Google accounts on your browser, I would recommend signing out of all and back into the one you use for Paperpile only before trying again. Please let us know.
Some clarifications:
References found online via our citing feature are saved to the library automatically once cited.
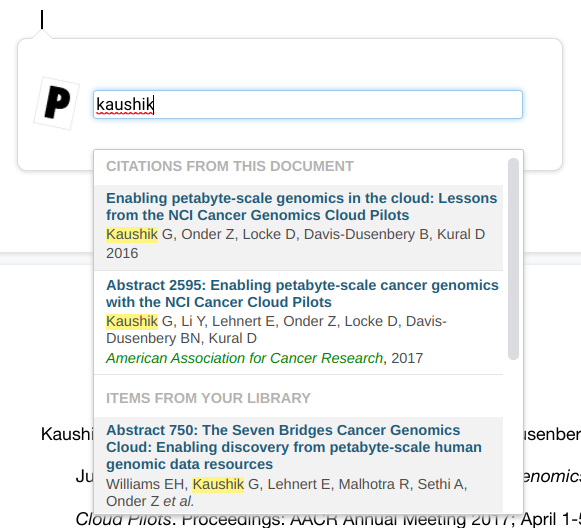
A reference cited previously in the same document appears under ‘Citations from this document’ like below (and the same version is used)
References already saved to your library appear under ‘Items from your library’ and should not create any duplicates, no matter how many times cited.
I am logged in to only one google account, so there should be no conflicts in that area.
I think the reason I am getting duplications is because I am pasting a URL address for a study, instead of an author’s name as shown in the sample. Therefore, everytime I input the same URL address for a study that is cited again, Paperpile showed only one selection in the populated results and not the various options you described, and also created a duplication in the library.
Many of the references I am citing in the manuscript have previously been saved to my Paperpile library. However, none of them appeared under “items from your library”, only as items found on the web if I input a URL instead of author’s name when using the app for adding citations.
I am happy to report today (8/9/21) that using only author name (and title) pulls up the correction information and avoided duplications in the library. I have successfully completed and submitted my article with more than 1200 citations. The Paperpile app worked most efficiently and seamlessly. I am extremely pleased with the time it saved me, and the high degree of accuracy achieved.
Thank you Vicente for you prompt professional assistance in helping me avoid hundreds of duplications in the library.
I’m back after 5 years with more of this issue. It is almost exclusive to books and their chapters. One I was able to solve because it had a DOI for each chapter, but many books don’t have that.
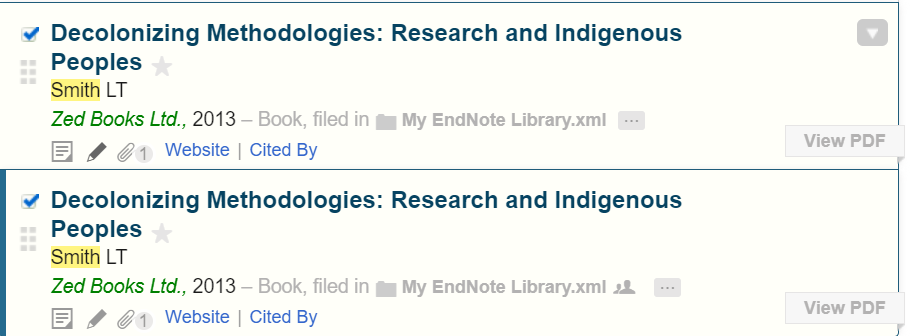
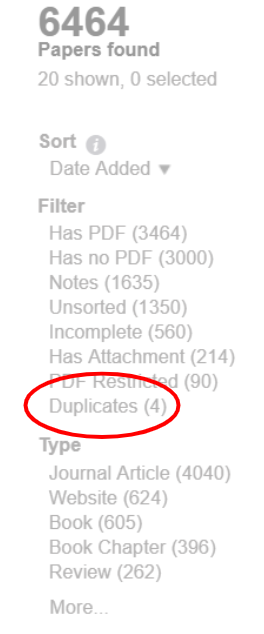
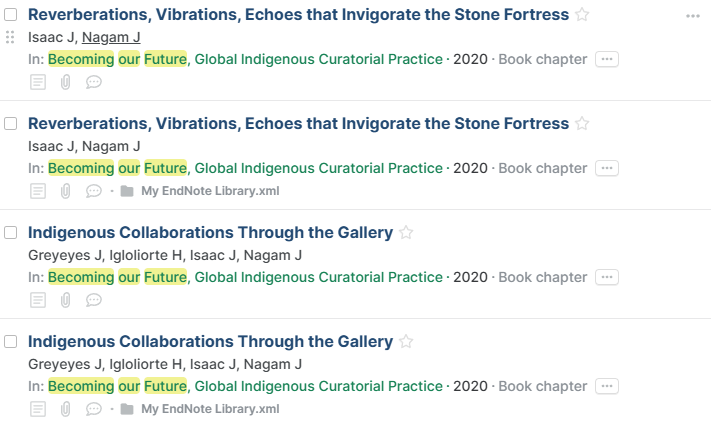
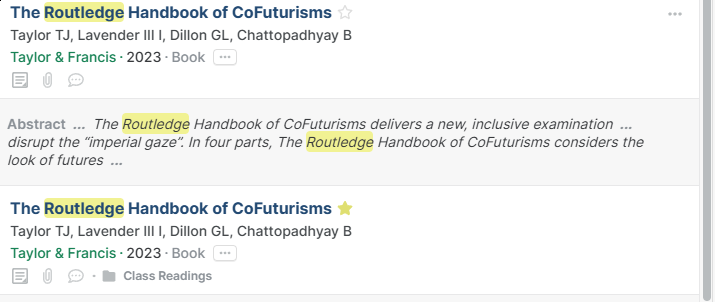
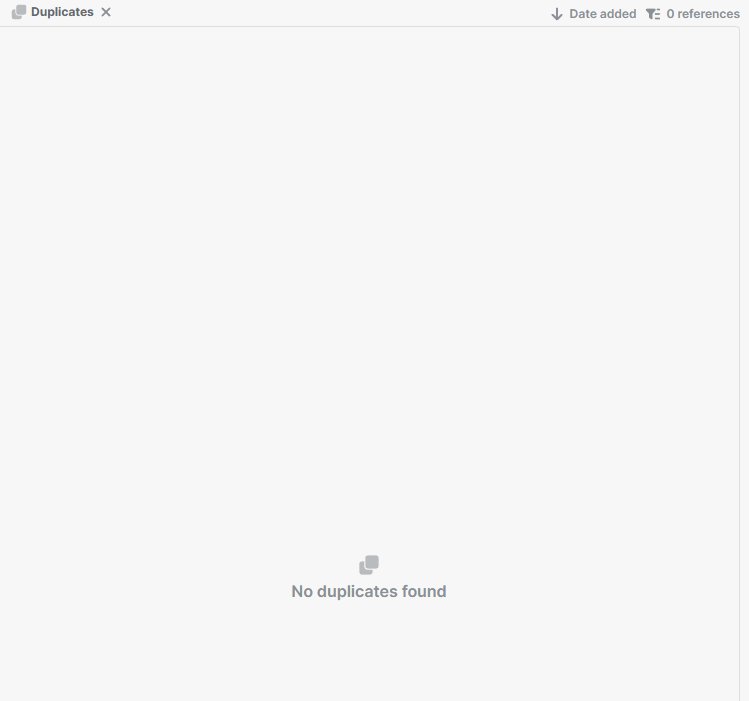
I have included a couple of screenshots of duplicates, but there are many. You can also see that they don’t show up in duplicates despite the info in them being exactly the same. Any other tips for forcing merges? I do think that just having an option to merge whether paperpile thinks it is a duplicate or not would solve a lot of these issues.
(this is a separate but related issue that I shared in another topic about duplicates)
I have been using the software for years and love it except for a few small bugs, by the way!