Hi Vicente,
Here are my answers to your questions:
• I think the slowness happens because too many documents and annotations have been added.
• There are no error messages, only lag.
• I have tried all configs of signing in and out, but it did not work.
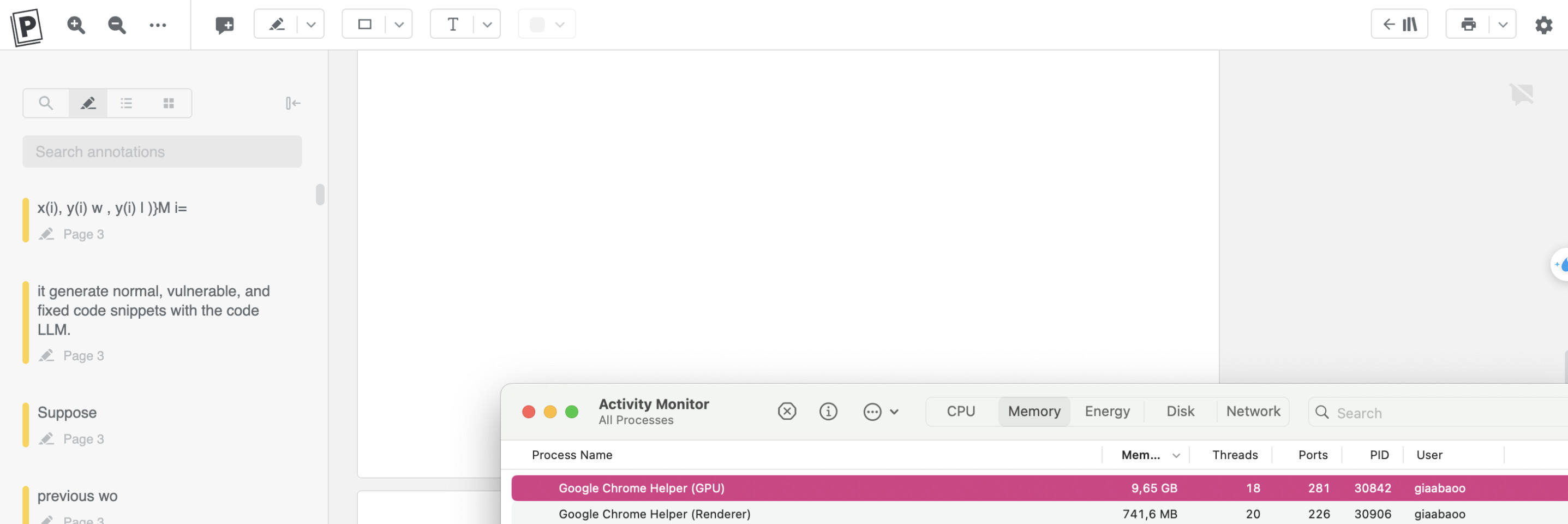
Here are the messages from pressing Cmd + J on one of the references that fails to load:
[{
"_id": "54a3f00e-3744-04a9-a874-3a9869405509",
"abstract": "Recent advances in code-specific large language models (LLMs) have greatly enhanced code generation and refinement capabilities. However, the safety of code LLMs remains under-explored, posing potential risks as insecure code generated by these models may introduce vulnerabilities into real-world systems. Previous work proposes to collect security-focused instruction-tuning dataset from real-world vulnerabilities. It is constrained by the data sparsity of vulnerable code, and has limited applicability in the iterative post-training workflows of modern LLMs. In this paper, we propose ProSec, a novel proactive security alignment approach designed to align code LLMs with secure coding practices. ProSec systematically exposes the vulnerabilities in a code LLM by synthesizing error-inducing coding scenarios from Common Weakness Enumerations (CWEs), and generates fixes to vulnerable code snippets, allowing the model to learn secure practices through advanced preference learning objectives. The scenarios synthesized by ProSec triggers 25 times more vulnerable code than a normal instruction-tuning dataset, resulting in a security-focused alignment dataset 7 times larger than the previous work. Experiments show that models trained with ProSec is 29.2% to 35.5% more secure compared to previous work, with a marginal negative effect of less than 2 percentage points on model's utility.",
"archivePrefix": "arXiv",
"arxivid": "2411.12882",
"attachments": [
{
"_id": "932c9c79-3574-405d-a7fd-65511f8c400c",
"mimeType": "application/pdf",
"pub_id": "54a3f00e-3744-04a9-a874-3a9869405509",
"source_filename": "2411.12882v1.pdf",
"filename": "All Papers/X/Xu et al. 2024 - ProSec - Fortifying code LLMs with proactive security alignment.pdf",
"md5": "4bafb42db9240d738b80861cf2034ea2",
"article_pdf": 1,
"filesize": 803174,
"created": 1732840157.6969998,
"s3_md5": "4bafb42db9240d738b80861cf2034ea2"
}
],
"author": [
{
"last": "Xu",
"first": "Xiangzhe",
"initials": "X",
"formatted": "Xu X"
},
{
"last": "Su",
"first": "Zian",
"initials": "Z",
"formatted": "Su Z"
},
{
"last": "Guo",
"first": "Jinyao",
"initials": "J",
"formatted": "Guo J"
},
{
"last": "Zhang",
"first": "Kaiyuan",
"initials": "K",
"formatted": "Zhang K"
},
{
"last": "Wang",
"first": "Zhenting",
"initials": "Z",
"formatted": "Wang Z"
},
{
"last": "Zhang",
"first": "Xiangyu",
"initials": "X",
"formatted": "Zhang X"
}
],
"autoCleaned": 1,
"citekey": "Xu2024-rj",
"copyright": "http://creativecommons.org/licenses/by/4.0/",
"created": 1732840155.3439999,
"dup_sha1": "cad881defcd3013b5d2ab40dce3be2d43f86ce00",
"eprint": "2411.12882",
"folders": [
"1277aa6e-0b08-40bb-b135-fee963e4d01b"
],
"foldersNamed": [
"AI4Code/Secure Code Generation"
],
"id_list": [
"sha1:eaee59142a4a81c9f95c13b478f12496863c2acd",
"dup_sha1:cad881defcd3013b5d2ab40dce3be2d43f86ce00",
"arxivid:2411.12882",
"url:http://arxiv.org/abs/2411.12882"
],
"incomplete": 0,
"journal": "arXiv [cs.CR]",
"labels": [
"e4cf407f-30fc-4155-bf46-10d2992394c8",
"69a1d565-6ed4-44ec-acde-994305c95fd6"
],
"labelsNamed": [
"secure code generation",
"reinforcement learning"
],
"owner": "AFB924642C5011EFAE72458F945E4932",
"pdf_restricted": 0,
"primaryClass": "cs.CR",
"published": {
"year": "2024",
"month": "11",
"day": "19"
},
"pubtype": "PP_PREPRINT",
"sha1": "eaee59142a4a81c9f95c13b478f12496863c2acd",
"subfolders": [
"All Papers/X"
],
"title": "ProSec: Fortifying code LLMs with proactive security alignment",
"url": [
"http://arxiv.org/abs/2411.12882"
],
"__render": {
"title": [
{
"type": "<div>",
"className": "pp-grid-title",
"children": [
{
"type": "<span>",
"content": "ProSec: Fortifying code LLMs with proactive security alignment",
"className": "pp-grid-titletext"
}
]
}
],
"author": [
{
"type": "<span>",
"content": "Xu X",
"className": "author",
"data": "Xu X:~XIANGZHE~XU~"
},
", ",
{
"type": "<span>",
"content": "Su Z",
"className": "author",
"data": "Su Z:~ZIAN~SU~"
},
", ",
{
"type": "<span>",
"content": "Guo J",
"className": "author",
"data": "Guo J:~JINYAO~GUO~"
},
", ",
{
"type": "<span>",
"content": "Zhang K",
"className": "author",
"data": "Zhang K:~KAIYUAN~ZHANG~"
},
", ",
{
"type": "<span>",
"content": "Wang Z",
"className": "author",
"data": "Wang Z:~ZHENTING~WANG~"
},
", ",
{
"type": "<span>",
"content": "Zhang X",
"className": "author",
"data": "Zhang X:~XIANGYU~ZHANG~"
}
],
"journal": "arXiv [csCR]",
"pubtype": "Preprint"
}
}]
Btw, many long documents fail to load, not just some.