Hello all,
I’ve been frustrated with the markdown export (no images, no bulk export) and generally slow pace of development for integrating with markdown-based tools, so I made a script that would do it for obsidian, here is the git repo.
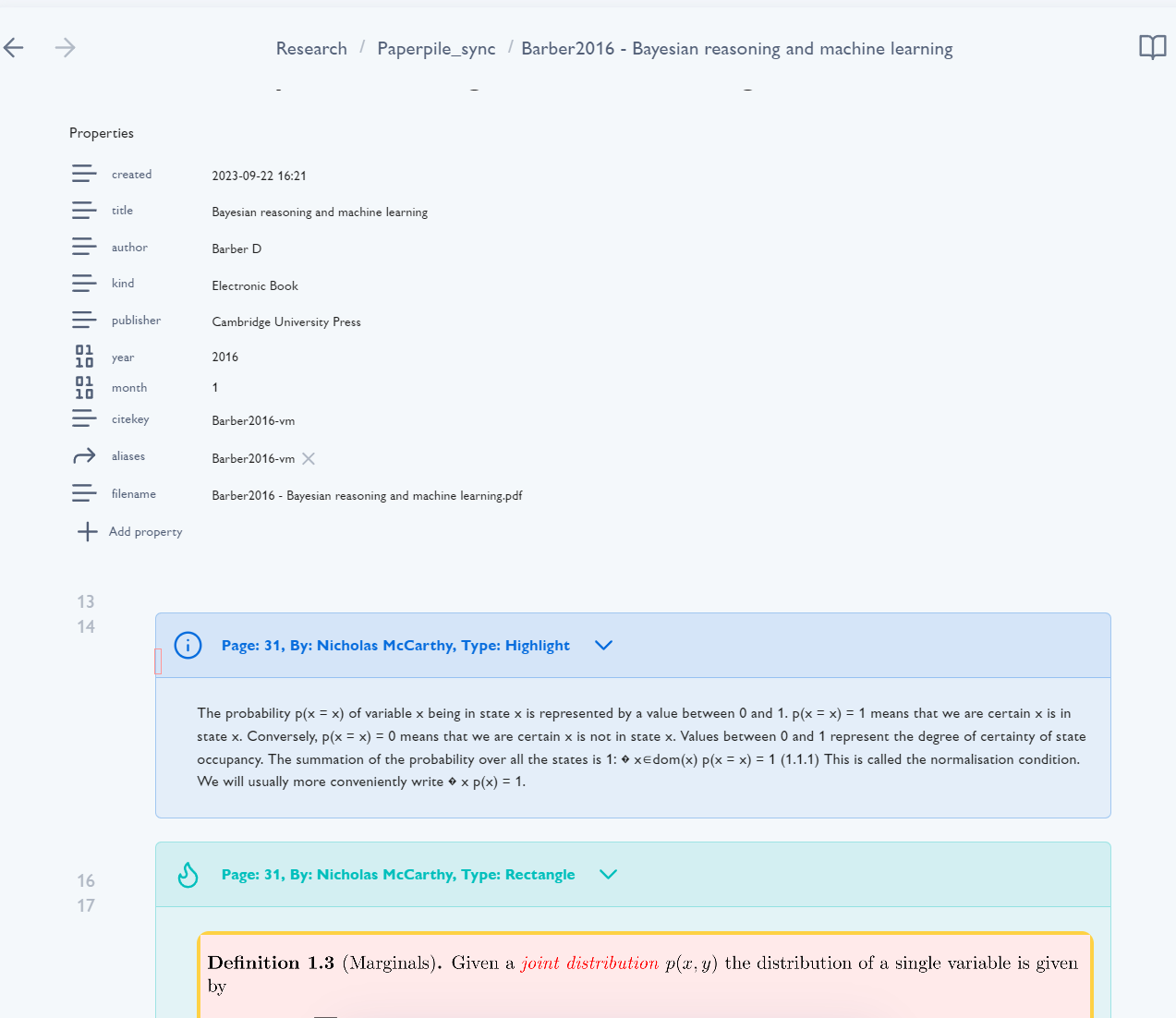
It is not a real obsidian plugin, but it is functional, extracts highlights, underlines, images, etc, and produces Obsidian markdown with properties like this:
If you are python-literate you can use it by installing the requirements.txt in your environment and running:
python main.py --input_dir /path/to/GDrive/Paperpile --json_path /path/to/paperpile.json --output_dir /path/to/Obsidian/
Notes/Comments:
-
The paperpile.bib file autoupdates in GDrive but frankly is awkward to parse, so I opted for basing it around the JSON export, which must be manually triggered (NB: Paperpile staff: can we have auto-export of this to GDrive? pretty please). In retrospect probably should have stuck with bib and implemented a better matcher, but there you go.
-
Annotations are saved to the PDF itself, so any new annotations/highlights made in Paperpile will be synced to gdrive and picked up on subsequent run of the script.
-
Any new pdfs added to paperpile will require a new JSON export containing that pdfs data before it can produce a markdown file.
-
Obsidian has a python script plugin which I haven’t tested this with (and probably it would require more work), but this reduces the workflow to:
- Export JSON data, if needed
- Run script
- The JSON export does not update the filename property with the paperpile template filename, even after resyncing the entire library to GDrive (Paperpile staff: not sure when/how this happens in the background, or if at all). This would probably be the best way to match json data with pdf (or if it was possible to sync pdfs as [citekey].pdf), but for the moment it does some fuzzy matching on citekey and title (obviously pretty hard-coded to my Markdown preferences and Paperpile settings).
There are a few features that would definitely be useful: templating the markdown properties and highlights, resync just one file, append to file on resync, etc.
I don’t have a lot of time to work on this (and it’s already upgraded my workflow immensely so I don’t need to go much further) – if anyone’s feeling brave please give it a go, otherwise I’d appreciate it if you filed an issue on the github page so I can see what to prioritize.
Finally, this was hacked together with no planning in about a day, and I see two viable paths for improvement:
- Make it a proper obsidian plugin: convert to nodejs, work with the .bib file instead of json, trigger script on detected file change - everything is now automated.
- A general purpose Paperpile markdown exporter, with better templating for specifying the output format.
Discuss…